Postgres Async Triggers
Table of Contents
##
Postgres Async Triggers
Run asynchronous side-effects on database events.
This blog post is accompanied by a demo repository on GitHub. Check it out here.
At hellomateo, we rely heavily on Supabase. And like any SaaS, we need to execute side-effects like sending a Webhook after a record changed. At first, we manually created database triggers that inserted jobs into the Postgres-based queue Graphile Worker after insert/update/delete. Not only was this a bad DX, we also hit scalability issues: the fetch job query from Graphile Worker dominated our database load, and the maxed out workers were not able to process jobs fast enough during peak times.
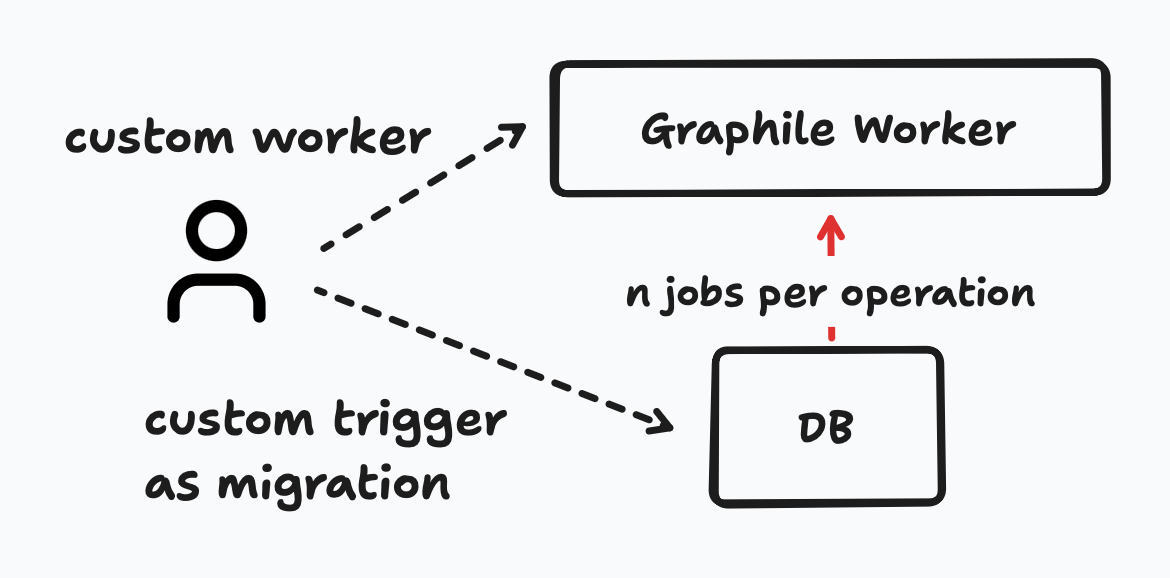
As an intermediary solution, we forwarded the critical jobs from Graphile Worker to QStash from Upstash. This helped with the maxed out workers at the cost of higher latency. As a messaging solution, higher latency is bad though. But still, things stabilised for the time being which gave us time to find a better solution.
Our goal was not only to solve the scalability issues, but also to improve DX. We wanted to reduce the surface area to write business logic. It should be easy to implement and test, and promote functional programming.
#
Exploring Change Data Capture
First, we looked into the scalability issue, and explored how to get database events into workers efficiently. The obvious option is Change Data Capture (CDC). CDC is a mechanism based on Write-Ahead-Logging provided by Postgres, more specifically logical decoding. It allows us to subscribe to any change happening in the database. It’s almost instant, and without overhead. But it’s a complex beast. To better understand the protocol, I created a quick proof of concept for a pipeline that batches the events before sending them to to a HTTP endpoint. While the PoC was fun and the approach is feasible, there are a lot of things to take care of, and we did not want to take on that extra complexity.
Next, we looked for tools that do the job for us. There is WalEx, an Elixir module to implement async triggers. Thats great, but we want to keep using Typescript. During that time, I also got in contact with Sequin. Their product is great, but its designed more as an infrastructure piece, and not towards application developers. We want to define our triggers in the code, and Sequin requires you to use their Dashboard or Terraform. There are other tools like Debezium, but their operational complexity is way too high. We decided that while CDC can be a great solution further down the road, its complexity is not justified yet.
#
The Simple Solution is Good Enough
We took a step back, and began tinkering on improving what we already have (and know well): How can we reduce the database load and reduce latency without compromising on horizontal scalability?
First, QStash had to be replaced. A HTTP based queue will always introduce latency we cannot afford. We quickly decided on BullMq, because we were already using Redis for caching and it’s a battle-proven queuing system with low double digit latency.
Now to the fun part: how to reduce the database load from Graphile Worker while increasing throughput? The only option is to start batching jobs. We have tables that trigger a lot of side effects, and each job was inserted from its own database trigger similar to this:
-- first side effect on `my_table`
create or replace function public.first_side_effect() returns trigger as $$
begin
perform private.add_graphile_worker_job (
'first_side_effect',
to_json(new),
priority := 'high'::private.graphile_worker_priority
);
return new;
end
$$ language plpgsql volatile set search_path = '' security definer;
create trigger first_side_effect
after insert on my_table for each row
when (new.my_column is true)
execute procedure first_side_effect();
-- second side effect on `my_table`
create or replace function public.second_side_effect() returns trigger as $$
begin
perform private.add_graphile_worker_job (
'second_side_effect',
to_json(new),
priority := 'high'::private.graphile_worker_priority
);
return new;
end
$$ language plpgsql volatile set search_path = '' security definer;
create trigger second_side_effect
after insert on my_table for each row
when (new.another_column is true)
execute procedure second_side_effect();
To use batching, we would need to have a single trigger that inserts a single batched job for each table and operation (AFTER [INSERT|UPDATE|DELETE]).
create or replace function public.run_side_effects() returns trigger as $$
declare
v_payload json := '[]'::json
begin
if new.my_column is true then
v_payload := v_payload || jsonb_build_object('tg_name', 'first_side_effect', 'new', to_json(new));
end if;
if new.another_column is true then
v_payload := v_payload || jsonb_build_object('tg_name', 'second_side_effect', 'new', to_json(new));
end if;
perform private.add_graphile_worker_job (
'side_effects',
v_payload,
priority := 'high'::private.graphile_worker_priority
);
return new;
end
$$ language plpgsql volatile set search_path = '' security definer;
create trigger first_side_effect
after insert on my_table for each row
when (new.my_column is true or new.another_column is true)
execute procedure first_side_effect();
Here, we move the when clauses into if clauses, and add the job to the list of jobs if it evaluates to true. The Graphile Worker then picks up the batched job, and forwards the payloads based on the tg_name. Note that this sample is missing a few important details, but more on that later.
We did a quick proof of concept and the impact was significant.
In our very first iteration, we had a single trigger function that used a lot of
execute formatto dynamically build the payloads based ontg_nameandtg_op, but that was even worse than not batching. Turns out, the execution context switch Postgres has to perform withexecute formatis very costly.
Now, how do we fix the DX? The database triggers are boilerplate, and we do not want to require a new migration every time we implement a side-effect anymore.
#
Crafting the DX: Implementing Async Triggers
Our goal with “async triggers” is to have a single place where a developer implements, tests and registers side-effects. For each trigger, we want to bootstrap the DDL for the actual database trigger that checks the conditions for each subscription and inserts a batch job.
The DSL we came up with is very similar to its equivalent in SQL:
import { builder } from '../../builder';
export default builder
.createTrigger('my-side-effect')
.on('my_table')
.withColumns('column_a,column_b')
.afterInsert("new.column_a is true")
.afterUpdate("old.column_b is not true")
.afterDelete()
.execute(
async (payload, dependencies) => {
// full typed:
// payload.new.column_a
// dependencies.supabaseClient.from()
},
{ concurrency: 300 }
);
Any async trigger declares up to three subscriptions on a table: insert, update and delete. Unlike database triggers, each subscription has its own optional when clause to filter on old and new. We also enforce the selection of columns to reduce the payload size. The execute function receives a typed event payload as well as globally declared dependencies.
The payload types are the only integration with Supabase. Everything else is just plain Postgres and Node.
All functions are registered on the server and collected on startup of the service. Before we start processing jobs, a set_subscriptions rpc is called that merges all subscriptions into the async_trigger.subscription table:
create table if not exists async_trigger.subscription (
id uuid not null default gen_random_uuid() primary key,
app_name text not null,
name text not null,
operation async_trigger.operation_type not null, -- INSERT, UPDATE, DELETE
schema_name text not null,
table_name text not null,
when_clause text,
column_names text[],
unique (name, operation, schema_name, table_name, app_name)
);
The subscription table itself has a trigger that fires after insert, update and delete to sync the database triggers. It dynamically generates and executes the create function and create trigger statements to create one trigger for every operation and table. The generated DDL for the async trigger defined above looks somewhat like this:
create or replace function async_trigger._publish_events_after_update_on_my_table ()
returns trigger
as $inner$
declare
v_jsonb_output jsonb := '[]'::jsonb;
-- shared payload
v_base_payload jsonb := jsonb_build_object(
'tg_op', tg_op,
'tg_table_name', tg_table_name,
'tg_table_schema', tg_table_schema,
'auth', jsonb_build_object(
'role', auth.role(),
'user_id', auth.uid()
),
'timestamp', (extract(epoch from now()) * 1000)::bigint
);
begin
if old.column_b is not true then
v_jsonb_output := v_jsonb_output || (jsonb_build_object(
'tg_name', 'my-side-effect',
'new', case when tg_op is distinct from 'DELETE' then jsonb_build_object(
'column_a', new.column_a, 'column_b', new.column_b
) else null end,
'old', case when tg_op is distinct from 'INSERT' then jsonb_build_object(
'column_a', new.column_a, 'column_b', new.column_b
) else null end,
) || v_base_payload);
end if;
-- if ...some other clause then
-- v_jsonb_output := ...
-- end if;
if jsonb_array_length(v_jsonb_output) > 0 then
perform private.add_graphile_worker_job(
'publish_events',
v_jsonb_output::json,
priority := 'high'::private.graphile_worker_priority
);
end if;
if tg_op = 'DELETE' then
return old;
end if;
return new;
end
$inner$
language plpgsql
security definer;
create trigger async_trigger_after_update
after update on my_table for each row
when (new.my_column is true or new.another_column is true)
execute procedure async_trigger._publish_events_after_update_on_my_table ();
In the trigger function, we add an if block for every “subscription” and populate the payload with all relevant data. There is also payload shared by all subscriptions like the current user.
The final job payload looks like this:
{
"auth":{
"role":"authenticated",
"user_id":"xx"
},
"new":{
"column_a":"value",
"column_b":"value"
},
"tg_name":"my-trigger",
"tg_op":"INSERT",
"tg_table_name":"event",
"tg_table_schema":"public",
"timestamp":1739550115638
}
Now, lets take a look at the “trigger that creates the triggers”. Its a bit more involved, so I added comments to help you go through it.
See the trigger in its full glory
create or replace function async_trigger.sync_trigger()
returns trigger as
$$
declare
v_app_name text := coalesce(new.app_name, old.app_name);
v_table_name text := coalesce(new.table_name, old.table_name);
v_schema_name text := coalesce(new.schema_name, old.schema_name);
v_when_clause text;
v_if_blocks text;
v_op async_trigger.operation_type;
begin
-- every subscription can have all operations, so we need to iterate through them
foreach v_op in array array['INSERT', 'UPDATE', 'DELETE']::async_trigger.operation_type[] loop
-- clean up any existing trigger and function
execute format(
$sql$drop trigger if exists async_trigger_after_%s%s on %I.%I;$sql$,
lower(v_op::text), v_test_postfix, v_schema_name, v_table_name
);
execute format(
$sql$drop function if exists async_trigger._publish_events_after_%s_on_%s%s;$sql$,
lower(v_op::text), v_table_name, v_test_postfix
);
-- check if we need to create a new trigger for the current operation
if exists (select 1 from async_trigger.subscription where table_name = v_table_name and schema_name = v_schema_name and operation = v_op) then
-- build the `WHEN` clause for the trigger
-- if there is at least one subscription for current operation without a when_clause, we do not add the when clause at all
-- otherwise, we combine them with OR, e.g. (old.col is true) OR (new.col is true)
v_when_clause := (
case when exists (
select 1
from async_trigger.subscription
where table_name = v_table_name and schema_name = v_schema_name and operation = v_op and (when_clause is null or when_clause = '') and app_name = v_app_name
) then null
else (
select string_agg(when_clause, ') or (')
from async_trigger.subscription
where table_name = v_table_name and schema_name = v_schema_name and operation = v_op and when_clause is not null and when_clause != '' and app_name = v_app_name
)
end
);
-- build the if block for every subscription
v_if_blocks := (
select string_agg(format(
$sql$
-- the WHEN clause is put here
if %s then
v_jsonb_output := v_jsonb_output || (jsonb_build_object(
-- the trigger name
'tg_name', %L,
-- dynamically build the new and the old data from the selected `column_names`
'new', case when tg_op is distinct from 'DELETE' then jsonb_build_object(
%s
) else null end,
'old', case when tg_op is distinct from 'INSERT' then jsonb_build_object(
%s
) else null end
-- merge with the shared payload from below
) || v_base_payload);
end if;
$sql$,
coalesce(nullif(subscription.when_clause, ''), 'true'),
subscription.destination,
subscription.name,
(select string_agg(format($s$%L, new.%I$s$, column_name, column_name), ', ') from unnest(subscription.column_names) as column_name),
(select string_agg(format($s$%L, old.%I$s$, column_name, column_name), ', ') from unnest(subscription.column_names) as column_name)
), e'\n') from async_trigger.subscription where table_name = v_table_name and schema_name = v_schema_name and operation = v_op and (v_is_test_app is false or app_name = v_app_name)
);
-- bootstrap the `CREATE FUNCTION` statement and execute it
execute format(
$sql$
create or replace function async_trigger._publish_events_after_%s_on_%s ()
returns trigger
as $inner$
declare
v_jsonb_output jsonb := '[]'::jsonb;
v_base_payload jsonb := jsonb_build_object(
'tg_op', tg_op,
'tg_table_name', tg_table_name,
'tg_table_schema', tg_table_schema,
'auth', jsonb_build_object(
'role', auth.role(),
'user_id', auth.uid()
),
'timestamp', (extract(epoch from now()) * 1000)::bigint
);
begin
-- this is where we put all the if blocks
%s
-- if at least one subscription evaluates to true, insert the job
if jsonb_array_length(v_jsonb_output) > 0 then
perform private.add_graphile_worker_job(
'publish_events',
v_jsonb_output::json,
priority := 'high'::private.graphile_worker_priority
);
end if;
p
if tg_op = 'DELETE' then
return old;
end if;
return new;
end
$inner$
language plpgsql
security definer;
$sql$,
lower(v_op::text),
v_table_name,
v_if_blocks
);
-- bootstrap the `CREATE TRIGGER` statement and execute it
execute format(
$sql$
create trigger async_trigger_after_%s
after %s on %I.%I
for each row
%s
-- execute the function we created above
execute procedure async_trigger._publish_events_after_%s_on_%s()
$sql$,
lower(v_op::text),
lower(v_op::text),
v_schema_name,
v_table_name,
case when v_when_clause is not null and length(v_when_clause) > 0
then 'when ((' || v_when_clause || '))'
else ''
end,
lower(v_op::text),
v_table_name
);
end if;
end loop;
return new;
end
$$ language plpgsql security definer;
Graphile Worker now simply iterates the jobs and forwards them to BullMQ. We use this canary release of Graphile Worker that implements local queues to maximise throughput and reduce database load at a theoretical latency cost. But we found that due to our single-digit job processing time and with at least two parallel workers, the downsides are negligible.
#
Summary
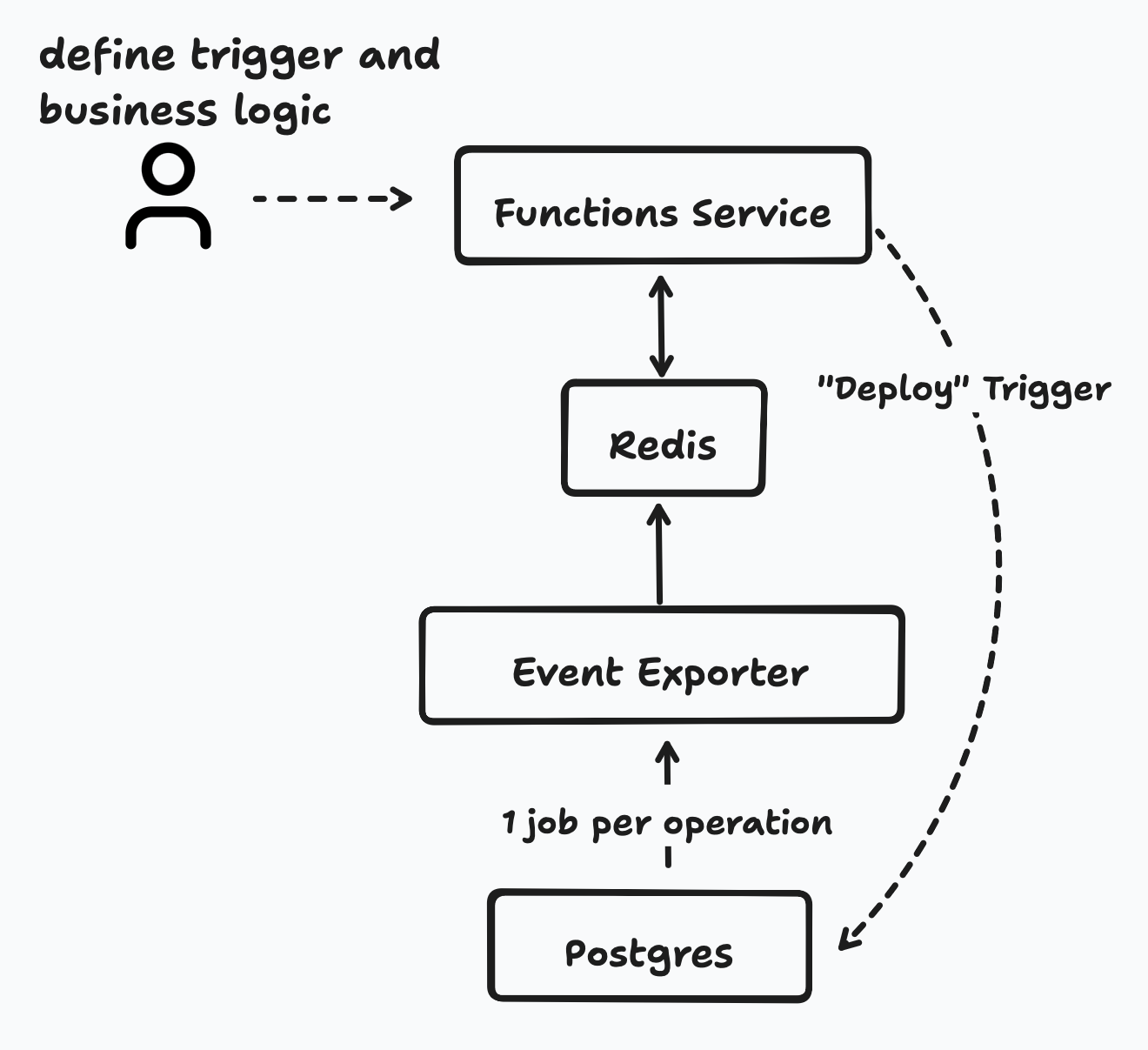
And that’s it for the async triggers! We successfully reduced the load on our database and increased throughput by batching the export jobs and thanks to the local queue mode. The latency is very low too: the BullMQ worker is executed in less than 100ms after the transaction completes on the database. We are also happy with the DX. A new developer should be able to implement business logic quickly. And the best part: we are still using only the simple tools.
#
Future Work
Right now, the framework is published as a shadcn-style demo. It is meant as a starting point for others to build their own. At some point, I hope to make this a more generic solution, where Graphile worker and BullMQ are just adapters for a generic „transport layer“. I would also love to see a variant that uses only Supabase infrastructure:
pg_netto get the jobs out of the databasepg_mqas the queue- Edge Functions to execute the jobs
We did not go this path because at that time queues were not released yet, we don’t use edge functions, and this architecture would not fulfil our throughput and latency requirements. Still, it is a viable option for many, and I hope PgFlow can evolve into this.
#
Additional Goodies
This blog post focusses on the async trigger implementation only. But the framework you can find in the demo repository is capable of more. We implemented an abstraction layer on top of BullMQ that allows for a boilerplate-free and type-safe implementation of business logic in a very functional manner. Functions can call, trigger and schedule other functions, and every handler receives globally defined dependencies that are created from the environment in a type-safe way. There is also a test framework to test both triggers and functions. Although a lot of things can still be polished, we are happy with its current status and hope it’s already of value for the community.
If you want to help build this, we are hiring in Berlin! You can reach me on philipp@hellomateo.de.